

El algoritmo Rete es un algoritmo de emparejamiento de patrones (pattern matching) creado por el Dr. Charles L. Forgy y publicado como parte de su tesis doctoral de la Universidad de Carnegie Mellon en 1979.
Se trata de un método eficiente para comparar una gran colección de patrones con una gran colección de objetos. Encuentra todos los objetos que se ajustan a cada patrón, esta técnica (pattern matching) es usada ampliamente en programas de inteligencia artificial, especialmente en los sistemas expertos donde el emparejamiento de patrones está dado en las reglas que componen la base de conocimiento, que es usada para lograr la inferencia y responder ante los hechos presentados.
En un sistema experto las reglas suelen presentarse de la forma si-entonces: si se cumple un conjunto de condiciones entonces se dispara la regla accionando la conclusión asociada, por ejemplo:
Si queremos saber si alguien es mayor de edad tendremos que revisar su edad, este dato es llamado hecho. Los hechos son esenciales para la inferencia pues las reglas operan con ellos, son esos objetos que se emparejan a los patrones y si no se presentan no se puede hacer inferencia. Para validar la mayoría de edad en una persona podemos usar la siguiente regla:
Si edad >= 18 Entonces mayor de edad
- La parte izquierda (Si) se compone de las condiciones necesarias unidas con operadores lógicos para afirmar una o varias conclusiones, en este caso solo hay una condición: que la persona tenga una edad igual o mayor a 18 años.
- La parte derecha (Entonces) está conformada por las consecuencias resultantes de cumplirse las condiciones: si la persona cumple la condición de edad entonces se afirma que es mayor de edad.
Algoritmos clásicos de inferencia
Un motor de inferencia se encarga de hacer el emparejamiento de patrones: empareja cada regla con los hechos dados en una memoria de trabajo para decidir cuales reglas pueden dispararse o ejecutarse. Usando algoritmos clásicos como encadenamiento hacia adelante o hacia atrás, este procedimiento es muy tardado y repetitivo ya que en estos algoritmos se revisa la base de conocimiento exhaustivamente, además, esta revisión debe realizarse constantemente al existir la posibilidad de cambios en la memoria de trabajo, ya sea que se agreguen o que se eliminen algunos hechos, lo que provoca que algunas reglas que anteriormente no eran satisfechas, ahora puedan serlo, y viceversa. La mayoría del tiempo, la memoria de trabajo no sufre grandes cambios, sin embargo se deben revisar todos los hechos en cada iteración, lo que sin duda representa un alto costo computacional innecesario; sería mejor guardar dichos cambios, mantener en memoria los emparejamientos ya logrados y solo hacer los cambios necesarios cuando se agreguen o se eliminen hechos. Aquí es donde Rete marca una gran diferencia en rendimiento.
Funcionamiento de Rete
El algoritmo Rete resuelve el problema del tiempo de respuesta implementando una red de nodos que representa el estado del sistema de emparejamiento y que solo actualiza aquellas partes afectadas con la adición o remoción de hechos. Para pocos cambios en la memoria de trabajo logra hacer el proceso de inferencia mucho más rápido. Además la estructura de la red se presta para hacer paralelo el algoritmo, lo cual resulta en un rendimiento aún mejor en culsters.
Construyendo la red
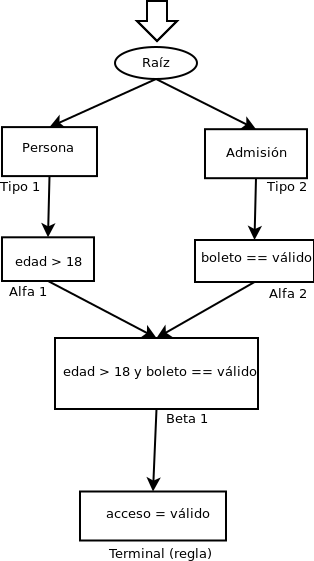
La red que genera Rete es un grafo dirigido sin ciclos conformado por nodos que representan las condiciones de las reglas. La red se compone de dos subredes: la red Alfa y la red Beta. La red Alfa se compone de nodos de una sola entrada, que representan los elementos de una condición. La red Beta, formada por nodos de dos entradas, define las uniones entre elementos.
El nodo raíz llamado también nodo Rete es el inicio de la red y el primero en crearse. Los nodos de tipo son los siguientes al nodo raíz, habrá un nodo de tipo por cada tipo de hecho. Los nodos Alfa son los siguientes en ser creados, representan las condiciones de una regla, por lo que existirán tantos como condiciones tenga cada regla y serán conectados a su respectivo nodo de tipo. Cada nodo Alfa estará asociado con una memoria usada para recordar los hechos emparejados. Después, los nodos Alfa son unidos por nodos Beta que representan la unión de condiciones, como solo tienen dos entradas, se requieren uniones parciales para condiciones compuestas largas. Cada nodo Beta tiene una memoria para guardar las uniones hechas.
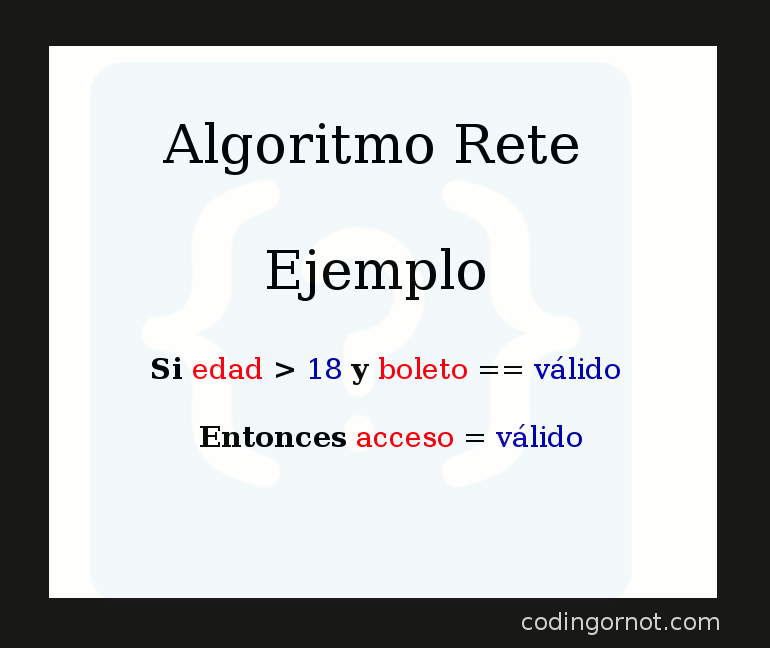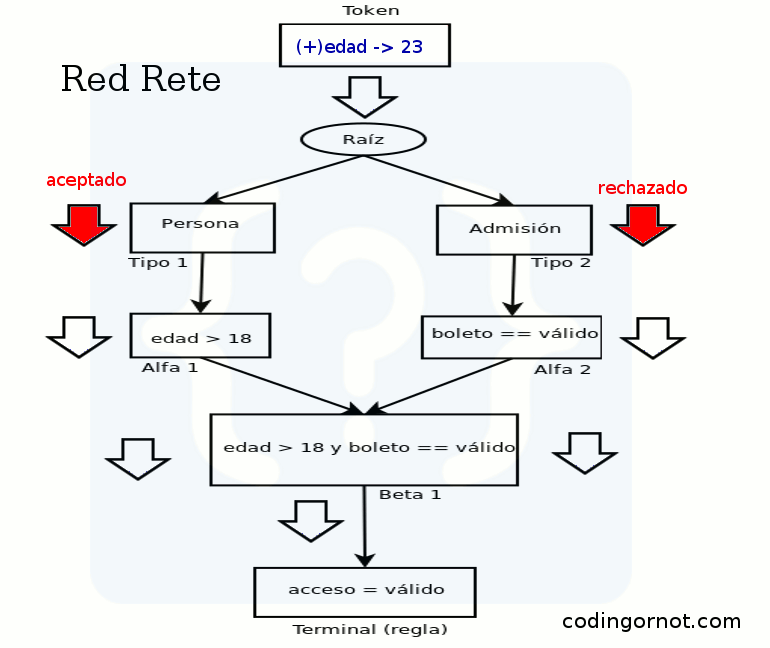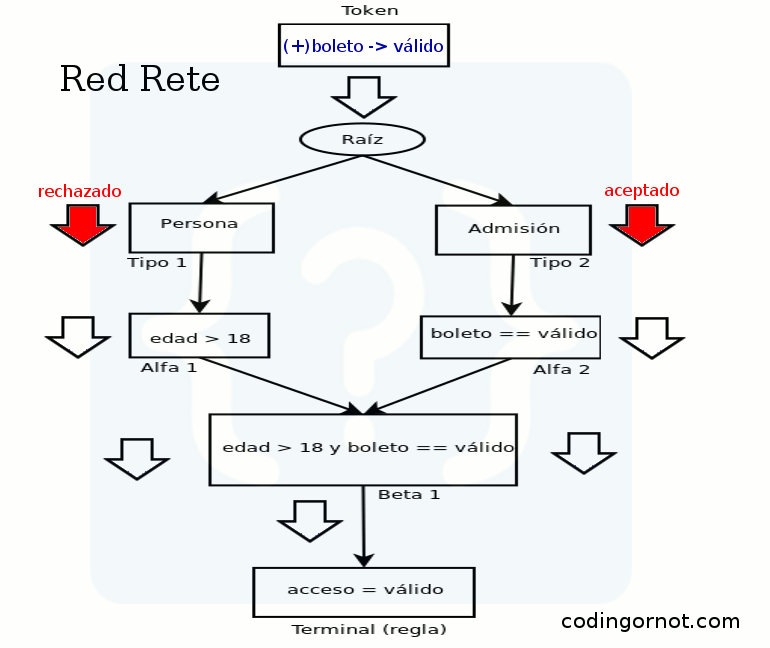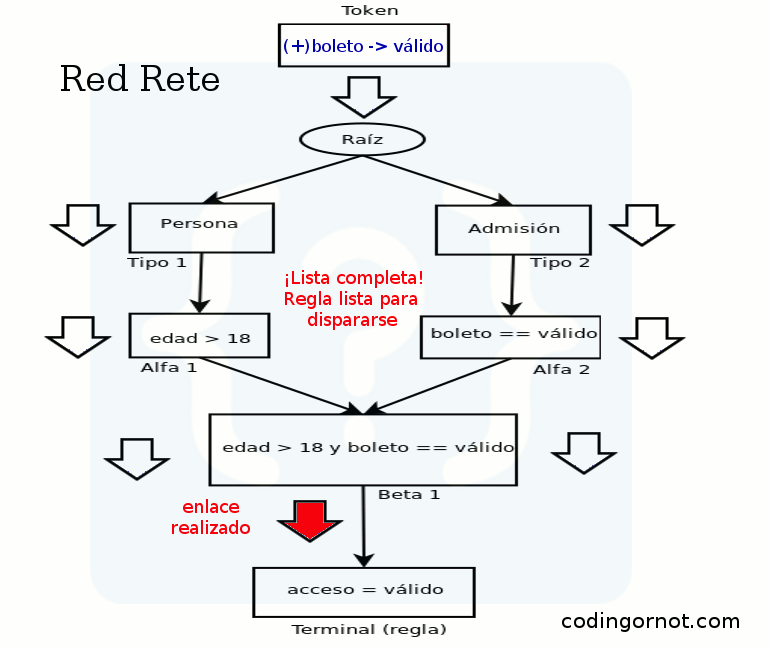
Al momento de agregarse o eliminarse un hecho se crea una ficha (token) con dos campos: un identificador de acción (“+” para agregar o “-” para eliminar) y el hecho en sí; y se manda al nodo raíz. De la raíz se propaga a cada nodo de tipo (se le envía una copia). Cada nodo de tipo pasa la ficha a sus nodos Alfa, aquí es donde se hace el emparejamiento (se verifica la condición). Después los nodos Beta determinan las posibles uniones para una regla o las rompe si el hecho se está eliminando y produce una regla incompleta. Si se logran hacer las conexiones necesarias cumpliendo las condiciones, la regla podrá ser disparada.
Veamos la red que se crea con la siguiente regla:
Si edad > 18 y boleto == válido entonces acceso = válido
Si agregamos los hechos necesarios podremos ver cómo se propaga la ficha por la red y finalmente se activa la regla para poder ser disparada. Veamos el ejemplo con una animación:
Conclusiones
El algoritmo Rete representa una excelente manera de hacer inferencia ya que logra obtener un gran desempeño en tiempo de respuesta tanto para bases de conocimiento pequeñas como grandes, sin embargo requiere mucha memoria. La estructura en red logra eliminar algunas redundancias de hechos participantes en las reglas, lo que nos da como resultado un grafo bien definido y compacto, al cual se le puede aplicar el algoritmo con varios hilos de ejecución y propagar más rápidamente la ficha.
Existen implementaciones muy famosas del algoritmo Rete, en seguida dejo los enlaces de algunas con el propósito de que puedas experimentar con ellas: