

En entradas anteriores explicamos qué es la computación distribuida. En esta entrada vamos a revisar la computación concurrente.
En la computación concurrente diferentes procesos o equipos se intercambian y acceden a un mismo recurso durante periodos de tiempo separados, es decir, todos acceden al mismo recurso pero de forma ordenada y nunca juntos. El acceso puede ser tan rápido, que desde el punto de vista del usuario pareciera que múltiples procesos acceden al recurso al mismo tiempo (o al menos esa es la finalidad de la concurrencia en equipos multitarea).
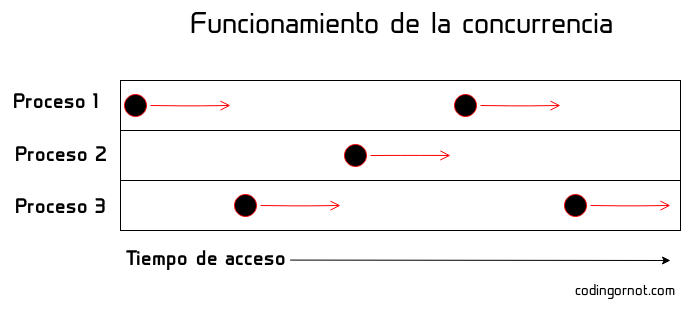
Problemas con la computación concurrente.
Es necesario contar con métodos para garantizar que la concurrencia se aplique correctamente, es decir, que solamente un proceso acceda al recurso al mismo tiempo; de otro modo el sistema será susceptible a errores y corrupción de datos. Otro problema muy importante de la concurrencia es la muerte por inanición, se dice que esto ocurre cuando a algún proceso jamás se le permite acceder al recurso y, por ende, jamás podrá concretar su ejecución. Para lograr que estos problemas no ocurran, se utilizan métodos de exclusión como semáforos y monitores junto con algoritmos de planificación.
Semáforos
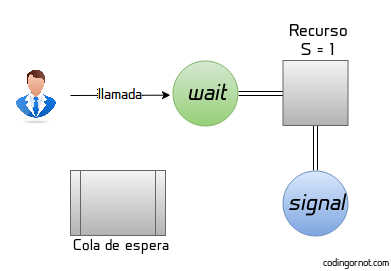
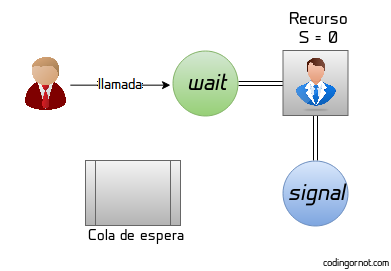
Los semáforos son variables especiales o tipos de datos abstractos utilizados para restringir el acceso a recursos compartidos. Son una forma muy simple y de bajo nivel de lograr la exclusión a un recurso ya que, generalmente se trata de una variable (denominada como S) que señala si el recurso está siendo utilizado o está disponible. Para modificar esta variable se utilizan dos funciones: wait y signal, comúnmente denotadas como P y V respectivamente. En general el funcionamiento de un semáforo es el siguiente:
S determina la cantidad de recursos disponibles o la cantidad de procesos que pueden acceder al recurso simultáneamente, si solo hablamos de un único recurso esta variable señala su disponibilidad. Cuando un proceso quiere utilizar el recurso, llamará a la función wait P; si el valor de S es 0 o un número negativo significa que el recurso está siendo utilizado, se decrementa el valor de S en 1 y quien acaba de llamar a wait se une a una cola de espera (se dice que el proceso se ha bloqueado). En cambio, si el valor de S es positivo, simplemente se decrementa el valor de S y el proceso toma control del recurso.
Cuando el dueño del recurso termina de utilizarlo llama a la función signal V. Esta función incrementa el valor de S y, si después del incremento S sigue siendo negativo eso significa que hay uno o más procesos dormidos/bloqueados esperando acceder al recurso, por tanto se despierta el siguiente que tomará control. Ejemplo del funcionamiento de un semáforo de un único recurso:


¿Qué son los monitores?
Un monitor es un tipo abstracto de dato diseñado para garantizar la exclusión a recursos críticos compartidos. A veces suelen ser confundidos con los semáforos ya que, hasta cierto punto son similares e incluso un monitor puede implementar semáforos internamente. Sin embargo, a diferencia de los semáforos que son variables de muy bajo nivel (solamente un contador), los monitores son objetos más complejos. Un monitor envuelve al recurso crítico y en ningún momento se le permite a los procesos acceder a él directamente, sino que deben de hacerlo a través de los métodos previamente programados en el monitor.
El funcionamiento interno del monitor depende completamente de quien lo implemente pero generalmente se utilizan semáforos junto con otros métodos y técnicas de exclusión para evitar los problemas que podrían presentarse con el uso único de semáforos.
Algoritmos de planificación
No basta con garantizar la exclusión, también es necesario contar con algoritmos que nos garanticen que los procesos no mueran por inanición y que todos (o su mayoría) tengan acceso al recurso. A continuación están algunos de los algoritmos más utilizados para planificación de procesos:
- FIFO: del inglés first in, first out (primero en entrar, primero en salir). Simplemente se le permite el acceso al recurso a los procesos según el orden en el que llegan.
- SJF: del inglés shortest job first (trabajo más corto primero). Cuando se conoce el tiempo estimado de ejecución de un proceso, se elije aquel que tiene el tiempo más corto de ejecución.
- SRTN: del inglés shortest remaining time next (menor tiempo de ejecución restante a continuación). Cuando llega un proceso nuevo a la cola, si su tiempo restante de ejecución es menor que el del que está en ejecución, se intercambian los procesos.
- Round robin: a cada proceso se le permite el uso del recurso por una cantidad de tiempo determinada (conocida como quantum) y se intercambian los procesos cuando uno utiliza el recurso por dicha cantidad de tiempo.
- Prioridades: a los procesos se les asigna una prioridad dependiendo de las necesidades del sistema. Se elige el proceso para ejecutarse dependiendo de la prioridad que estos tengan.