

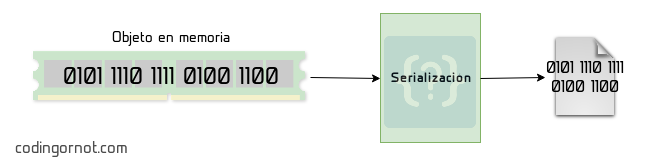
La serialización es un proceso mediante el cual podemos convertir objetos de un programa en ejecución en flujos de bytes capaces de ser almacenados en dispositivos, bases de datos o de ser enviados a través de la red y, posteriormente, ser capaces de reconstruirlos en los equipos donde sea necesario. Al hablar de “objetos”, no me refiero únicamente al significado que estos tienen en la POO; un objeto es cualquier estructura de datos, función o método que esté en memoria.
Uno de los principales objetivos de la serialización es permitir crear flujos de bytes independientes de la arquitectura de los equipos en los que se utilicen, inclusive, que los objetos puedan ser reconstruidos en otros programas sin importar que el lenguaje con el que son escritos sea diferente al que se usó para crear el objeto originalmente.
Marshalling puede usarse como sinónimo de serialización, sin embargo, debes de tener cuidado porque en lenguajes de programación como Java, marshalling se refiere a la acción de almacenar el estado de un objeto junto con su código, mientras que serializar es solamente crear copias de objetos como flujos de bytes. El procedimiento inverso de la serialización es la deserialización o unmarshalling.
Importancia de la serialización
La importancia que tiene este procedimiento no se limita al envío de bytes por la red. Son varias las razones por las que muchos lenguajes de programación como C, C++, Java, C#, Python y Perl (entre otros) han incluido paquetes, módulos o API enfocadas en serializar datos. En seguida señalo algunas de esas razones:
-
- Permite hacer llamados a procedimientos remotos (RPC).
- Sirve para identificar cambios de datos en ejecución.
- Podemos almacenar objetos en dispositivos de almacenamiento como discos duros.
- Si un programa en ejecución termina inesperadamente o detecta algún problema, puede cargar un respaldo completo o parcial.
- Permite intercambiar objetos entre programas independientes.
Problemas y dificultades con la serialización
Si el objeto que estamos intentando serializar contiene apuntadores a otros objetos o datos en memoria, el proceso de serialización puede volverse un poco -o muy- complicado porque, a pesar de que enviemos el objeto, es probable que las direcciones a las que hacen referencia los apuntadores no sean las mismas en los equipos donde se reconstruya, ni siquiera hay garantía de que hayamos enviado los objetos a los que referenciaban.
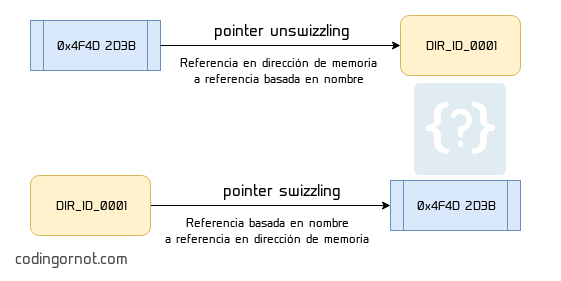
Para solucionar el problema anterior, muchos lenguajes de programación recurren a un proceso llamado pointer unswizzling. Dicho proceso se encarga de generar identificadores especiales en base al nombre o a la posición de un objeto en memoria, es decir, convierte direcciones de memoria físicas en lógicas. Después de aplicar pointer unswizzling, cuando un objeto serializado apunta a otro, ya no lo hará con direcciones de memoria, sino con un identificador especial. Si un objeto al que se hace referencia no se encuentra en memoria, el programador o la API podría encargarse de realizar una petición al equipo que realizó el envío original. El proceso de convertir referencias lógicas a apuntadores o direcciones de memoria físicas es llamado pointer swizzling.
Otro problema común de la serialización nace de la diferencia en arquitecturas entre los equipos que trabajen con ella. Para solucionarlo puede optarse por un middleware que se encargue de enmascarar las diferencias entre los equipos. También se puede recurrir a protocolos que ayuden a los equipos a saber cómo reconstruir un objeto.
La serialización también rompe la opacidad de los datos abstractos y podría ocasionar problemas por permitir convertir miembros encapsulados en flujos de bytes. Imagina que serializaste una instancia de la siguiente clase Animal:
class Animal {
private:
string especie;
int esperanza_de_vida;
// Más miembros privados
public:
string dameEspecie(){return this->especie}
// Más métodos públicos
}
Tiempo después actualizaste la clase porque te diste cuenta que, en lugar de almacenar cadenas con la especie del animal, era mejor almacenar identificadores con la llave (key) que la especie tiene en un map global:
class Animal {
private:
int id_especie;
int esperanza_de_vida;
// Más miembros privados
public:
string dameEspecie(){
std::map<int, string>::iterator it;
it = ESPECIES.find(id_especie);
if (it != mymap.end())
return this -> *it
}
// Más métodos públicos
}
Los cambios que realizaste no ocasionarán errores en las líneas donde haces llamados al método aunque sean al de la versión anterior, esto porque cambiaste la implementación pero el método sigue teniendo el mismo identificador y devolviendo un string.
Si intentas cargar a memoria un objeto que serializaste de la primera versión de la clase, ocurrirá un error puesto que en ella no existían ni el campo id_ especie, ni el código para extraer la especie del map. Con la opacidad de datos abstractos y el encapsulamiento mantenemos oculta cierta información a la que accedemos por medio de métodos o subrutinas, esto ayuda a garantizar la compatibilidad entre diferentes versiones de una API o programa, pero la serialización rompe este concepto al volver a los objetos susceptibles a los cambios de las clases (aunque sean en miembros privados). Existen frameworks/API para intentar solucionar este problema, por ejemplo protobuf de Google.
Eso ha sido todo, espero que te haya servido. Para cualquier duda o comentario sobre el tema, no dudes en hacérmelo saber, see ya!
Estupendo articulo!!!